
We’ll start in section one with an overview of each type of architecture, and arrive at some key principles of what good architecture really is. In section two, we’ll look at the challenges we face with architectural decisions, especially focusing on how different parts of our applications are coupled together. In section three, we’ll draw on our principles to find solutions to the challenges we identified, drawing some aspects of microservices into our monolith applications to get the best of both approaches without major rework.
1. Architecture
The monolith
Monoliths commonly evolve as we build an application bottom-up – adding controllers, views, and new database entities. We tend to couple the various parts of our system together, seeing system interactions as mirroring the related nature of the business or organisation structures that the application supports (our domain). This knowledge is discovered gradually throughout the development process, rather than being fully known from the start.
IPC NEWSLETTER
All news about PHP and web development
Many popular web application frameworks are well-suited to writing monolithic applications (e.g., Laravel, Symfony, Flask, Spring). These frameworks can, of course, be used as components in a microservice architecture as well, but reading common samples, tutorials, or viewing how their codebases are structured points more often towards a monolith.
When you combine the ease of building without a detailed plan and the abundance of well-suited frameworks, it’s no surprise that monoliths are built.
The same characteristics that apply to a codebase often also apply to the data store used for the monolith. This will usually be in the form of a relational database. Whilst they can use specific relationships in the form of foreign keys (and the benefits associated with indexing), it’s generally possible to join or filter on any field. This once again permits an application to choose its data architecture as it grows into it, not restricting where data can live or how it can be related, but allowing flexibility and changes in structure.
Why do we build monoliths?
This “bottom-up” growth of an architecture can be an advantage because when we explore our domain, adding new features is generally just a new file away. Monoliths tend to have the simplest software lifecycle. They exist as single repositories in version control, making them simple to share or build out in feature branches. Components for common tasks such as authentication and logging are readily available. A monolith will keep most server-side logic in a single language, and can all be tested in a single test suite (usually written in the same language).
Depending on the language, a monolith may be deployed as easily as sending files to a remote server. It may require a simple packaging step (such as a zip file) or a compilation step (e.g., transpiling in TypeScript or compilation in Go). In all cases, the resulting server can be replicated by a configuration running locally, and the application is often transferable between remote servers.
At the base level, the monolith is a reliable way to build software, whether as an individual or a team. They are easy to start up, prototype, and ship. Given this potential for an easy life with a monolithic application, how do things look with microservices?
Microservices
Every system has an architecture, whether we designed one or not. So if we want to make good architecture choices, we have to evaluate the options available to us, including monoliths, microservices, and other factors.
In a microservice system, we split different functionalities into distinct applications. Microservices platforms intend to reduce the likelihood of coupling between unrelated components by keeping them separated. This makes it possible for services to be in different repositories and to be built, tested, and deployed independently. Splitting the codebase into different services often aligns with different teams that may work on these services. It can even allow different services to be written in different languages/frameworks.
By aligning services with teams, microservices aim to enable more agility, as, ideally, a team can make improvements or solve bugs in their own service without the risk of affecting others. These changes should be quicker to verify, as each application would presumably be smaller than the entire stack of a monolith, with fewer tests to run and a lower risk of developing complexity.
Communication between services
Services will communicate via synchronous or asynchronous means. Synchronous communication tends to use some form of network request (HTTP or gRPC) and is analogous to a function call within a single system. This form of communication will be similar to how a lot of API tools between unrelated parties (so-called 3rd party APIs) work, with defined requirements (in the form of OpenAPI specifications or contract tests) in terms of requests and responses.

Asynchronous communication may use a stream (e.g., Kafka), a queue (RabbitMQ), or a notification system (AWS SNS). The chosen mechanisms for asynchronous communication all have quite different use cases – streams or notification systems allow sending a message without any intent of receipt, whilst queues tend to have the goal of executing a specific task. Asynchronous communications may mean one service can communicate without knowledge of another, but for actual work to happen in response to an event on a stream, a consumer must have insight into what messages are likely to be sent.
If microservices have different codebases, they may also have different data stores. Indeed, the increasing popularity of microservice architectures has happened around the same time as more distributed methods of data storage, like NoSQL databases, have entered the general consciousness of developers. With independent data stores, services can adapt better to their own frequencies of reads & writes and use data structures that fit their use cases better. For example, a payment system may be highly transactional and need very reliable write performance and atomicity. This is different from an emailer service that needs to perform complex segmentation queries in batches, but whose durability may matter less as long as the overall throughput is maintained.
Monolith & microservice misconceptions
The Wikipedia page describing Monolithic Applications makes a poor case for them. Indeed, it seems to be written by someone who doesn’t like the concept of a monolith: “A monolith is less available, less durable, less changeable, less fine-tuned, and less scalable than a well-designed distributed system.”
This use of “less than” places monoliths in a negative space. In every way, they are lesser than their microservice counterparts. However, we could look at the microservice architecture in the same way:
It’s only as available (and as durable) as its least available (and durable) synchronously coupled service. It’s only as changeable as we have an appetite to maintain versions of our internal APIs for, and it’s scalable as long as we keep the same access patterns we thought of when we started building it.
In fact, the only part about monoliths that rings true is the last part: “well-designed.”
The rise in popularity of microservices may come in part from their use at large enterprise organisations, where teams and systems reach a scale where attempting to use monolithic architectures may severely hamper progress due to the challenges of cross-team communication. This is not a present worry for development teams in the majority of organisations, but we should be careful not to follow a pattern simply because it is discussed by people working on prestigious teams or projects.
In the next section, we’ll explore a few key principles and evaluate how both architectures measure up against them. We’ll then look at how to apply these principles to improve our applications, regardless of the architectural approach we choose.
Key principles
- Coupling creates complexity in systems. Whilst we want to reduce this, many real-life interactions (which our systems are modelled around) are themselves complicated and messy, so we can never reduce complexity all the way.
- We need coupling to be clear to both sides of any service interaction and the different people who may be working with it.
- Smaller services will always have an advantage in speed of testing or deployment. However, if they introduce version dependencies between services, this advantage can be significantly reduced.
- Decoupled data stores can suffer the same problems of consistency and hidden coupling as service codebases. There may be times when independent services can agree to work with the same data store if that store can have a consistent schema.
Firstly, let’s see the problems monoliths come up with when we evaluate the architecture.
2. Challenges
Cracks in the monolith
In software applications, coupling refers to connections between pieces of code where the execution of one piece of code requires the presence of another.
For example, in many software-as-a-service applications, the “user” may be tightly coupled to many other concepts. Users may own specific data entries, have authentication services, manage billing, and even administer the software. In this context, the “User” entity and associated logic may be coupled to most or all parts of the codebase. Modifications to the “user” as an entity, or to the concept of what a user is/does, may impact any part of the software. The tight coupling of “user” results in brittle software; a small break in one part may result in the whole application breaking.
Codebase coupling
With all software being written in one language and one codebase, coupling is likely to occur. This is especially true if building from the bottom up. As we start to add features, we reuse parts of code that seem similar, prematurely abstracting them and later resulting in a mess of configuration options. Consider the following example:
class Utils {
/**
* Output our address components
*/
public static function addressFormatter(Address $address) :string {
return implode(', ', array_filter($address->toArray()));
}
}
But we re-use it more and more, adding parameters to meet a widening range of use cases, and progressively making the internal logic harder to reason about:
class Utils {
/**
* Output our address components
*/
public static function addressFormatter(Address $address, string $separator = ',', bool $hide_number = false, bool $show_country = false) :string {
$arr = $address->toArray();
if ($hide_number){
unset($arr['number']);
}
if ($show_country){
$arr[] = $address->getCountry();
}
return implode($separator, array_filter($arr));
}
}
Eventually, a change in one part of the application will unexpectedly break something elsewhere. While this example may be contrived, tight coupling is often a natural consequence of architectures that evolve alongside application logic without clear boundaries. Monoliths are particularly well-suited to this style of development, which is why they often end up being built this way.
Database coupling
Just as services can become coupled, so too can the database entities underlying a monolith. These act as a form of asynchronous coupling between parts of the system that may not appear directly connected in the code. It’s often only when multiple components rely on the same data and expect it to behave consistently that we realize seemingly unrelated parts of the codebase are, in fact, tightly linked through shared database structures.
As well as adding the normal risks of maintainability, coupling may also result in redundant data, fields on a table of 1,000 rows just used for one or two cases, because of a specific niche use case.
Another risk of keeping all data stored in a single source relates to how the infrastructure is handled. As different features require improved query performance, better transactional locks, or higher throughput, the entire platform must scale in all directions to accommodate each requirement.
IPC NEWSLETTER
All news about PHP and web development
Size constraints
Some of the software lifecycle advantages of monoliths may also become disadvantages over time. The singular test suite may take longer to run (even if it can be parallelised), and because the monolith may permit any part of the code to use any other part, all tests need to be run even for small changes. Not only this, but coverage becomes more important, as manual testing or QA on a change may not catch unintended changes. Depending on the form of deployment, changes may also take longer to deploy as the application increases in size. Again, the whole application must be redeployed for each change (or wholesale rolled back in the case of a defect in a single feature).
Given these limitations, monoliths are often seen as a viable approach, at least up to a certain application size. But this raises a difficult question: where exactly is the tipping point where a monolith starts to break down under its own weight? While many projects begin small, it’s common for prototypes to end up in production without the rewrite they clearly need. This reality makes it tempting to start with the architecture we hope to end with. But how well do microservices hold up when judged against the same principles?
The awkward thing about microservices
The idea of independent services, potentially written in different languages, that are fast to build, test, and release, is appealing. It’s especially attractive when you’ve been wrestling with a highly coupled monolith that breaks in new and unpredictable ways with every small change we make.
However, just because it’s no longer easy to reuse a function in an unrelated component, our microservices often still end up coupled together through their chosen mechanisms of communication. The considerations that go into good architecture are still important, but just utilising microservices won’t be enough.
Communication coupling
Coupling is especially easy with synchronous systems, as API calls effectively replace function calls. This can have multiple drawbacks, firstly in the surprising area of error handling and fault-tolerance.
If one service relies on another synchronously, the uptime of the overall system reduces to the lowest uptime within the system. This is not necessarily worse than a monolith, where the whole system may be heavier and thus harder to keep up, but it doesn’t suggest the uptime may be better either.
Even with a good level of uptime, networks are more error-prone than function calls within an application. Remote procedure calls can fail for various reasons and cause an error state. This means each application must be able to work out retries or determine appropriate fallback behaviour when its dependent service is unavailable.
Another challenge for synchronous systems lies in the contract between the services. If one service wishes to modify the data it would like to receive, or data it wishes to send in response, the other system may need to adjust its own interactions. Versioning of the API requests and responses will be required so that, as one system is upgraded, other systems continue to operate with it.
If both services are managed by one team, it may be possible to operate with only a single version difference between two coupled systems; upgrade system A, then upgrade system B. However, when multiple systems depend on system A, and especially if those are managed by different teams, system A may need to support multiple versions simultaneously to allow dependent systems time to update.
Asynchronous communications
Asynchronous interactions are more manageable, but only if they truly are asynchronous. For example, in the context of pub-sub or stream-based architectures, it’s generally assumed that a service may publish information without any requirement that this is acknowledged or acted on. In an ideal setting, this means a service can publish whatever it wants, even multiple versions or permutations of the same message, and it is up to the consumer to choose what to act on.
These ideal settings are challenged when running up against real-life examples, where two actions may not need to happen instantly after one another, but where there is still an expectation that one follows the other.
A checkout system is a common part of many platforms, and may seem simple enough. We take customers through reserving items in a basket, entering shopping details, and making a payment. Once the payment clears, we dispatch the order and send a receipt.
However, even in a seemingly straightforward case, it’s worth asking: which parts are truly asynchronous? Each step typically depends on the successful completion of the previous one. The only arguably “optional” part might be the receipt email. But if that consistently fails, customers are likely to be unhappy. Whether this system is split into multiple services or consolidated into a single process doesn’t eliminate the challenge that the entire workflow is expected to work reliably. Putting multiple services into one process can sometimes obscure real issues, making them harder to detect and resolve.
Decoupling databases
If reducing coupling seems difficult, that’s because it genuinely is. One reason monoliths tend to grow over time is that the businesses or organisations that our software is a map of often evolve in a similarly unplanned and unstructured way. We add extra services or introduce exceptions to established patterns to seize specific opportunities or mitigate particular risks.
The same is true of all the data that our organisations create; databases become a form of asynchronous communication (and thus coupling) in their own right. We may decide to move all user authentication to an auth service with its own data store for user information. As users interact with unrelated services, we can take a copy of key information for the user and add it to custom settings pertinent to the specific application. What do we do in this case when a user wishes to modify their email address or password? Maybe that data lives just with the authentication layer, but does that then become the service that has to send them email notifications, or the newsletter?
We’ve likely all used services where navigating to a single feature involves being bounced across multiple subdomains, so many that even the browser seems dizzy by the time we get there. In reality, the idea of one user accessing multiple features tends to couple the system together anyway, as users expect a consistent, coherent experience across the entire platform.
The data-access patterns of an application built with microservices can also become a challenge. We may have designed one part of the system for high transactional load and the other for batch analytics, but what happens when we want to analyse the correlation between our newsletter signups and recent purchases, or how many people unsubscribe after a payment failure? As with monolithic codebases, there is an advantage to putting all our data in one place and working out how we want to use it later, as often we don’t know the facts up front.
3. Solutions
Putting it together
Monoliths have one set of problems, while microservices come with another. Neither exists solely to fix the problems of the other, and both can be well designed (or not). One could argue that the key advantage of microservices is that when things go wrong, the issues tend to surface much earlier than they would in a monolith, where cracks can take longer to appear. However, this is only an advantage if those early warning signs lead to meaningful change, rather than simply doubling down on microservices and assuming they’re the right answer.
If we are aware of the pitfalls inherent in how a monolith grows, especially in how code and data can become coupled, then we can avoid these aspects without needing to completely change what form of architecture we are using.
By understanding the pitfalls of how a monolith grows, particularly how tightly coupled code and data can become, we can then avoid those issues without necessarily abandoning the form of architecture we are using altogether.
Putting together these principles, it’s clear that whether we’re working with an existing monolith or choosing to build a new one. We can learn from the microservice world to adopt better architecture.

Reducing code-level coupling
Whilst code-level coupling is easier to introduce than communication coupling, it’s also easier to spot. This is especially true in smaller teams that may work on many different components in an application, but it can also apply to larger ones working on monolithic applications as well.
One way to do this is by writing our code according to its Domain, rather than its type. Many applications are written with directory structures like:
src
|- api
|- user
|- order
|- entities
|- user
|- order
|- exceptions
|- user
|- order
|_ services
Whereas we can actually organise them like:
src
|- user
|- api
|- exceptions
|- entities
|_ services
|- order
|- api
|- exceptions
|- entities
|_ services
In doing this, we start to be able to apply rules – items in the “user” directory should not be able to call public methods or create objects of classes in the “order” directory.
Some languages have features to help enforce this. For example, the popular PHP static analysis tool psalm has the @psalm-internal flag, allowing a namespace to be specified where a call is permitted:
namespace UserDomain {
class AddressService {
/** @psalm-internal UserDomain */
public static function formatPostcode(string $string):string{
return '';
}
}
}
namespace OrderDomain {
class InvoicePrinter {
public static function address(string $postcode):string{
return \UserDomain\AddressService::formatPostcode($postcode);
}
}
};
When Psalm analyzes the above code, it will output the error:
The method UserDomain\AddressService::formatPostcode is internal to UserDomain but called from OrderDomain\InvoicePrinter::address
Not all languages have a similar pattern. However, for those that don’t, it’s often a requested feature. C# has the internal keyword, much as methods or fields may be declared protected or private.
Declaring relationships
It’s perfectly reasonable that services need to interact with each other, whereas the “internal” concept (whether enforced in code or not) prevents this in the same way two independent services would prevent it. Just like independent services, some form of communication pattern is necessary. Once again, this reintroduces coupling, but when done in a codebase, it is possible to make coupling very explicit using the paradigm of event handlers.
In this case, a method that carries out an action dispatches an event. Rather than this being an interaction with a communication protocol such as stream, it is handled within the application code:
class UserService {
public function changePassword(User $user){
// code that changes password
$this->dispatch(new ChangedPassword($user->getId()));
}
}
In the application bootstrap:
// Audit-service bootstrap
$dispatcher->addListener(ChangedPassword::class, function($event){
$user_id = $event->getId();
$this->logAuditTrail($user_id);
})
Many frameworks (e.g., Symfony or Laravel in PHP) provide event listeners as part of their framework, but they are relatively straightforward to implement as well. This creates a specific relationship viewable in code (rather than via API contracts, or by trying to read five different repository configurations to work out what is responding to what) that still enforces segregation of domains.
One useful tip when dispatching events is to only use scalar data in the event. This pushes services to rely on the simplest data points from another service and adds another barrier to just utilising internal concepts of a data store, which may have to be changed in the future.
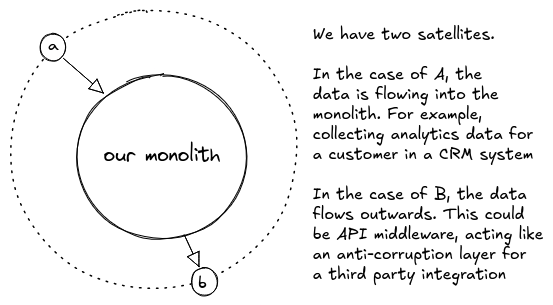
Satellite services
While it’s encouraging to see that domain isolation and clarity of coupling can be introduced in a monolith without rewriting it to microservices, there are still benefits to microservices that can’t be reproduced easily using just a monolith. Smaller services can be tested and deployed more rapidly. They can also use different infrastructure to suit specific use cases.
Fortunately, this benefit is still open to monoliths if we use the idea of satellite services. A satellite service combines elements of monolith and microservice. The satellite is functionally independent from the monolith. It can have its own repository (although shipping the code alongside the monolith may be simpler for our team), be in its own language, and have its own test suite. What makes this different from a microservice is that we avoid the risk of coupled communication by keeping the data flowing in a single direction.
The main challenge from microservices communication is the concept of a request and response, and so each service interaction requires the understanding of two sets of data formats. Service A needs to send data in the right format and understand the response. If service B can also talk to service A, this problem is doubled.
When using a satellite service, we try to offload a very specific piece of data processing to another service without creating dependencies in both directions.
IPC NEWSLETTER
All news about PHP and web development
Satellite use cases
For example, imagine a customer analytics application that wants to start ingesting data directly from third-party merchants. While this adds a valuable new feature, it also introduces a sudden infrastructure burden. The monolith that was originally built to support a data visualisation Saas platform is unlikely to handle a firehose of metrics from third-party websites, especially when that data requires real-time processing and storage.
This is where the satellite service comes in. Given a very specific known schema for how the application already needs its data processed and stored, a service can be written to provide this third-party ingest function separately, offloading processing to custom infrastructure before delivering the data to the base system. The data flows in one direction, and the satellite doesn’t need to know anything about how the data is eventually used. In the event the schema does need to change, the satellite will need to be upgraded first, but doesn’t need to be versioned; it can just output data in both old and new formats, and the application can choose which cases it uses.
The same would be true of a satellite service existing only to extract some specific piece of data and provide it to a third party (for example, as part of API middleware). Once again, if the data structure in the monolith is to change, the satellite must adapt first and be able to handle both old and new formats. There is no need here to maintain versions long term, as previous versions are set in stone and can remain without an extra maintenance burden, because the versioning is in the satellite, not the monolith. With a clear relationship between small satellites and the main monolith, we avoid the challenge of a mesh of services all needing different versions of one another (the so-called “big ball of mud”).
E(xtract) T(transform) L(oad)
When microservices can use independent databases without running into the challenge of coupling between data stores, they gain some advantages. A big aspect is that many databases excel at specific requirements, but of course, no single database excels at everything.
The two main patterns of database usage are transaction processing and analytics. We often do these operations on the same or similar blocks of data, and relational databases can handle both well. However, depending on our throughput and load distribution, we may find that intensive write operations require one type of scaling while intensive read ones require another. Furthermore, these operations can interfere with each other; reads may be blocked by row-level blocks during writes, or the server may become overwhelmed in terms of processing power or memory when handling both operations.
In a traditional relational database, we can often solve this problem using read replicas, carrying out analytics on a secondary storage mechanism that can lag behind the primary, but in a way that this lag doesn’t cause problems for the data we’re trying to extract. The two databases can be sized differently, though they are often tied together in the same network, share the same data (mostly), and run on the same database platform.
A pattern we can learn from microservice architectures and apply back to our monolithic applications is Extract, Transform & Load. In these cases, we run a process that doesn’t just clone data between identical data stores on different hardware, but lets us modify the data and normalise or denormalise it for a different purpose. We can build ETL systems using a range of different options:
- ETL within a single database using triggers – useful for denormalising data to create more effective structures for specific search or analytics queries.
- Using our transactional store on a NoSQL serverless platform like Amazon DynamoDB, we can read from a stream output to load data into one or multiple different SQL or other data stores, providing the ideal structure for each case (e.g., changing a nested document set into a range of rows across relational tables).
- For data stored in file or object storage as JSON, use batch processing to move this into a database for analytics, such as Snowflake or Redshift.
- Some tools, such as AWS Athena or Glue, also allow us to run SQL-like operations on file storage, using a series of crawlers or indexes that are run on a schedule.
By recognising that the way we generate or store data can be decoupled from how we use it, even within a monolithic platform or one data store, we gain more options when it comes to how we use our data while avoiding the risk of different use cases interfering with one another.
4. Conclusion
The real challenge in building systems that remain manageable isn’t whether we choose a monolithic or microservices architecture, but how well we understand and manage the dependencies within our application, and, by extension, within our domain. If we’ve taken advantage of the simplicity and rapid development benefits of a monolith, we can still avoid the pitfalls of tight coupling by carefully structuring our code and enforcing clear boundaries around which parts of the application can interact, even within a single codebase.
We can use the best infrastructure or language for specific jobs by adopting satellite services, where we avoid excessive intercommunication problems by keeping data flowing in a single direction.
We have to acknowledge that our data storage will still be part of our communication layer and a place where accidental coupling can occur. However, clear rules within our application about where data belongs can help mitigate this, and our satellite services can be part of reformatting data for specific use cases when we need it.
If we’ve already built microservices, understanding our structure may not have fixed all our coupling. It is helpful to reformat or, at least, aim to make these dependencies explicit wherever they occur.
It’s natural for the architecture of the software we build to evolve around us. We can steward this evolution to manage complexity and reduce coupling, making it clear where our key dependencies are. Without needing to tear down our monolithic applications, we can take advantage of domain separation, satellite services, and data management strategies, building a healthy application by understanding the core principles of how services grow and communicate together.
moments: replacing a list of constants with an Enum, adding readonly to a DTO, or swapping a fragile switch for a robust match expression.
These features – Enums, Readonly, Named Arguments, Match, Property Hooks, and Attributes – are just a small set of the goodies made available in recent PHP releases, but they provide clearer intent, safer defaults, and expressive data. They turn quiet, insidious bugs into loud, fixable errors. They reduce boilerplate and let us focus on the business logic that actually matters.
So, here is the challenge: Pick one feature from this article. In your next pull request, try to replace a set of constants with an Enum, or use named arguments in a confusing function call. Start small. You will find that these small upgrades accumulate into big quality-of-life wins for you and your team.
Enjoy a better app, and an easier life!
Author
🔍 Frequently Asked Questions (FAQ)
1. When should a team choose a monolith over microservices?
A monolith is often the better choice when teams need rapid iteration, low coordination overhead, and a simple deployment model. It works well when the domain is still evolving and boundaries are not fully understood. A well-structured monolith can scale effectively if coupling is carefully managed. Architectural success depends more on dependency clarity than on service count.
2. How does coupling impact system complexity and maintainability?
Coupling increases complexity when changes in one component require changes in others. Tight coupling makes systems fragile, harder to test, and more difficult to refactor safely. Hidden coupling—especially through shared databases or reused abstractions—creates long-term maintenance risks. Managing coupling explicitly is essential for sustainable architecture.
3. Do microservices eliminate coupling or just move it?
Microservices reduce direct code-level dependencies but introduce communication-level dependencies. Synchronous APIs create runtime availability coupling, while asynchronous systems require shared understanding of message contracts. Versioning and inter-service coordination can become complex over time. Microservices shift coupling into communication patterns rather than removing it entirely.
4. How can coupling be reduced inside a monolith without rewriting it?
Coupling can be reduced by organizing code around domains instead of technical layers. Enforcing internal visibility rules prevents unrelated domains from directly accessing each other’s logic. Using event dispatching makes dependencies explicit rather than implicit. Clear boundaries inside a single codebase can provide many benefits associated with microservices.
5. What are satellite services and when are they useful?
Satellite services are independent services that extend a monolith with one-directional data flow. They handle specialized tasks such as data ingestion, transformation, or external integration without creating bidirectional dependencies. This avoids complex versioning meshes between services. Satellite services combine infrastructure flexibility with architectural simplicity.




